0.0.1 🎯 Objectifs d’apprentissage
- Implémenter un GLM Poisson pour la fréquence en Python
- Implémenter un GLM Gamma pour la sévérité
- Gérer les interactions et effets non-linéaires
- Valider avec la déviance, l’AIC et les lift curves
- Comparer les performances GLM vs Machine Learning
📚 Prérequis : Modules 5 (fréquence/sévérité) et 8 (principes tarifaires, intro GLM)
⏱️ Temps estimé : 3 heures
1 GLM Poisson pour la fréquence
1.1 Implémentation avec statsmodels
import statsmodels.api as sm
import pandas as pd
import numpy as np
# Charger les données
df = pd.read_csv("portefeuille_auto.csv")
# Variables explicatives (dummies pour les catégorielles)
X = pd.get_dummies(df[['age_classe', 'zone', 'puissance_classe']], drop_first=True)
X = sm.add_constant(X)
# Variable réponse
y = df['nb_sinistres']
# Offset = log(exposition) pour gérer les durées partielles
offset = np.log(df['exposition'])
# Modèle GLM Poisson
model_freq = sm.GLM(y, X, family=sm.families.Poisson(), offset=offset)
result_freq = model_freq.fit()
print(result_freq.summary())1.2 Interprétation des coefficients
Les coefficients s’interprètent comme des log-relativités :
\[\ln(\lambda_i) = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \ldots + \ln(\text{exposition}_i)\]
La relativité d’une modalité est \(\exp(\beta_j)\) :
| Variable | Coefficient | Relativité | Interprétation |
|---|---|---|---|
| Intercept | -2.50 | - | Fréquence de base = 0.082 |
| age_18-25 | 0.62 | 1.86 | +86% de risque vs référence |
| zone_Paris | 0.37 | 1.45 | +45% vs référence |
| puissance_8+ | 0.10 | 1.11 | +11% vs référence |
2 GLM Gamma pour la sévérité
2.1 Implémentation
# Filtrer les sinistres uniquement (sévérité > 0)
df_sin = df[df['nb_sinistres'] > 0].copy()
X_sev = pd.get_dummies(df_sin[['age_classe', 'zone', 'type_garantie']], drop_first=True)
X_sev = sm.add_constant(X_sev)
y_sev = df_sin['cout_moyen']
# GLM Gamma avec lien log
model_sev = sm.GLM(y_sev, X_sev, family=sm.families.Gamma(link=sm.families.links.Log()))
result_sev = model_sev.fit()
print(result_sev.summary())💡 La prime pure GLM
\[\text{Prime pure}_i = \hat{\lambda}_i \times \hat{s}_i = \exp(X_i^f \hat{\beta}^f) \times \exp(X_i^s \hat{\beta}^s)\]
C’est le produit des prédictions du modèle fréquence et du modèle sévérité. Grâce au lien log, les deux se multiplient naturellement.
3 Interactions et non-linéarité
3.1 Interactions
Une interaction signifie que l’effet d’une variable dépend du niveau d’une autre :
# Ajouter une interaction âge × zone
X['age_jeune_x_paris'] = X['age_18-25'] * X['zone_Paris']📝 Exemple
L’effet “jeune conducteur” est peut-être plus fort à Paris (trafic dense) qu’en rural. Sans interaction, le modèle suppose que l’effet âge est le même partout. Avec interaction, on capture cette différence.
3.2 Effets non-linéaires
Pour les variables continues (âge, km), on peut utiliser des splines ou des classes :
# Découper l'âge en classes
df['age_classe'] = pd.cut(df['age'], bins=[18, 25, 35, 45, 55, 65, 99],
labels=['18-25', '26-35', '36-45', '46-55', '56-65', '65+'])4 Validation du modèle
4.1 Métriques de qualité
| Métrique | Description | Bon modèle |
|---|---|---|
| Déviance | Écart entre modèle et données | Plus basse = mieux |
| AIC | Déviance + pénalité pour complexité | Plus bas = mieux |
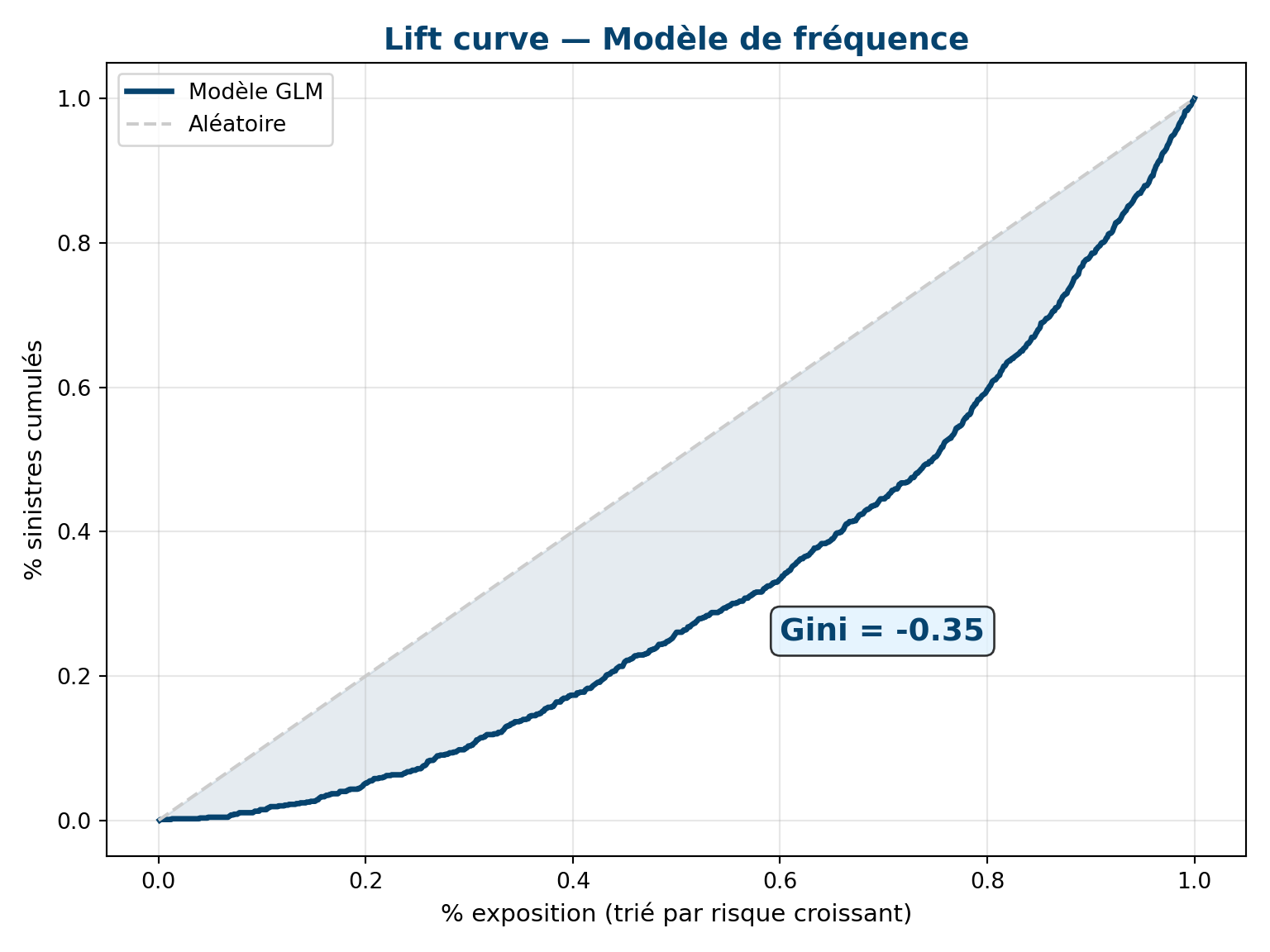
| Lift curve | Pouvoir discriminant du modèle | Courbe éloignée de la diagonale |
| Gini | Concentration du pouvoir prédictif (0-1) | > 0.3 pour la fréquence |
4.2 Lift curve
⚠️ Overfitting
Un modèle avec trop de variables ou d’interactions peut sur-ajuster les données d’entraînement. Toujours valider sur un jeu de test séparé (ou par validation croisée) et comparer l’AIC sur train vs test.
5 GLM vs Machine Learning
5.1 Comparaison
| Critère | GLM | XGBoost / Random Forest |
|---|---|---|
| Interprétabilité | Excellente (relativités) | Faible (boîte noire) |
| Performance prédictive | Bonne | Souvent meilleure |
| Exigences réglementaires | Standard accepté | Nécessite SHAP/LIME |
| Gestion des interactions | Manuelle | Automatique |
| Risque d’overfitting | Faible | Plus élevé |
| Adoption en assurance | Universel | En progression |
💡 En pratique
La plupart des assureurs utilisent le GLM comme modèle de référence (benchmark) et le ML comme outil d’amélioration. On commence par un GLM, puis on teste si un modèle ML apporte un gain significatif. Si oui, on utilise SHAP pour l’interpréter et le justifier auprès du régulateur.
Synthèse
5.1.1 🎯 Les 5 concepts à retenir
- GLM Poisson + offset pour la fréquence — Coefficients = log-relativités
- GLM Gamma pour la sévérité — Même framework, même interprétation
- Interactions à ajouter manuellement — Tester si l’effet varie selon le contexte
- Lift curve et Gini pour valider — Le modèle discrimine-t-il bien les risques ?
- GLM = benchmark, ML = amélioration — Toujours comparer et justifier
Auto-évaluation
Question 1 : Pourquoi utiliser un offset dans le GLM Poisson ?
Réponse : L’offset \(\ln(\text{exposition})\) corrige les durées partielles. Un assuré couvert 6 mois a 2× moins de chances de sinistrer qu’un assuré couvert 12 mois. Sans offset, le modèle confondrait les assurés à faible risque avec ceux à faible exposition.
Question 2 : Comment interpréter un coefficient de 0.62 pour “age_18-25” ?
Réponse : Relativité = \(\exp(0.62) = 1.86\). Un jeune conducteur de 18-25 ans a un risque de fréquence 86% plus élevé que la classe de référence, toutes choses égales par ailleurs. Sa composante fréquence dans la prime sera multipliée par 1.86.
Question 3 : Qu’est-ce qu’une lift curve et comment la lire ?
Réponse : On trie les assurés par risque prédit croissant (axe X = % exposition) et on trace le % cumulé de sinistres (axe Y). Un bon modèle concentre les sinistres dans les déciles de risque élevé : la courbe s’éloigne de la diagonale. Le Gini résume cet écart (0 = aléatoire, 1 = parfait).
Question 4 : Quand le ML apporte-t-il un vrai gain par rapport au GLM ?
Réponse : Quand il y a des interactions complexes non captées par le GLM (ex : effet croisé âge × zone × puissance × km), des non-linéarités fortes, ou beaucoup de variables. En pratique, le gain est souvent de 2-5% de Gini, ce qui peut représenter des millions d’euros sur un grand portefeuille.
Glossaire
| Terme | Définition |
|---|---|
| Offset | Terme fixe dans le GLM pour corriger l’exposition |
| Déviance | Mesure d’écart du GLM aux données |
| AIC | Critère de sélection de modèle (déviance + pénalité complexité) |
| Lift curve | Graphique du pouvoir discriminant |
| Gini | Coefficient de concentration du pouvoir prédictif (0 à 1) |
| Interaction | Effet croisé entre deux variables |
| SHAP | SHapley Additive exPlanations — interprétabilité ML |